

How To Use K&n Air Filter Cleaner
Overview
- What Is K Means Clustering
- Implementation of K means Clustering
- WCSS And Elbow Method To discover No. Of clusters
- Python Implementation of Grand means Clustering
K ways is one of the most popular Unsupervised Machine Learning Algorithms Used for Solving Classification Problems. K Means segregates the unlabeled data into various groups, called clusters, based on having like features, common patterns .
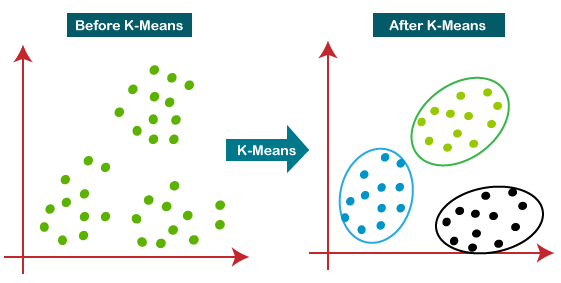
Table of Contents
- What Is Clustering
- What Is K Means Algorithm
- Diagrammatic Implementation of KMeans Clustering
- Choosing The Correct Number of Cluster
- Python Implementation
1. What Is Clustering?
Suppose nosotros have N number of Unlabeled Multivariate Datasets of diverse Animals like Dogs, Cats, birds etc. The technique to segregate Datasets into various groups, on basis of having similar features and characteristics, is being chosen Clustering .
The groups being Formed are being known as Clusters. Clustering Technique is being used in diverse Field such equally Epitome recognition, Spam Filtering
Clustering is being used in Unsupervised Learning Algorithm in Machine Learning as it can exist segregated multivariate data into diverse groups, without whatever supervisor, on basis of common design hidden inside the datasets.
2. What Is K Ways Algorithm
Kmeans Algorithm is an Iterative algorithm that divides a grouping of n datasets into k subgroups /clusters based on the similarity and their mean distance from the centroid of that particular subgroup/ formed .
Grand, hither is the pre-defined number of clusters to be formed by the Algorithm. If K=3, It means the number of clusters to be formed from the dataset is 3
Algorithm steps Of K Means
The working of the K-Means algorithm is explained in the below steps:
Footstep-ane: Select the value of Chiliad, to decide the number of clusters to be formed.
Step-two: Select random 1000 points which will act as centroids.
Stride-3: Assign each data point, based on their distance from the randomly selected points (Centroid), to the nearest/closest centroid which will form the predefined clusters.
Step-four: place a new centroid of each cluster.
Step-5: Repeat step no.3, which reassign each datapoint to the new closest centroid of each cluster.
Step-vi: If any reassignment occurs, and so get to step-4 else become to Stride 7.
Pace-7: FINISH
3. Diagrammatic Implementation of M Means Clustering
STEP 1:Let's choose number k of clusters, i.e., K=ii, to segregate the dataset and to put them into dissimilar corresponding clusters. Nosotros volition choose some random two points which volition act as centroid to form the cluster.
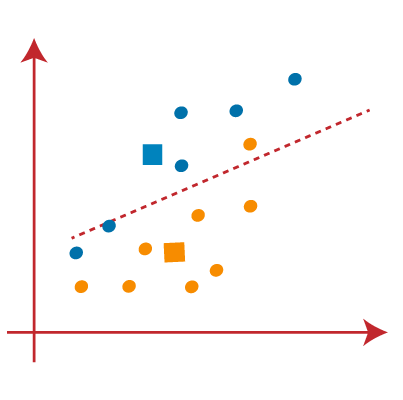
Pace 2: Now we will assign each data betoken to a besprinkle plot based on its distance from the closest K-point or centroid. Information technology will be done past drawing a median between both the centroids. Consider the beneath image:
Footstep 3:points left side of the line is near to blueish centroid, and points to the right of the line are shut to the yellowish centroid. The left one Course cluster with blueish centroid and the right one with the yellow centroid.
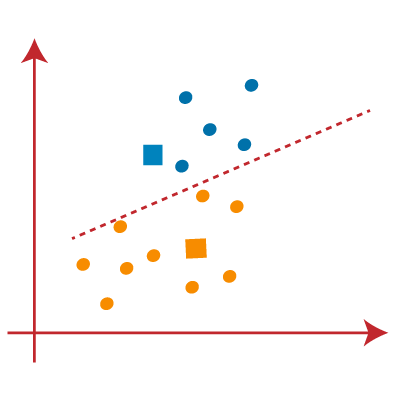
Stride iv:echo the process past choosing a new centroid. To choose the new centroids, we will find the new heart of gravity of these centroids, which is depicted beneath :
Footstep 5:Next, nosotros will reassign each datapoint to the new centroid. We volition repeat the same procedure as above (using a median line). The yellow information indicate on the blue side of the median line volition be included in the blue cluster
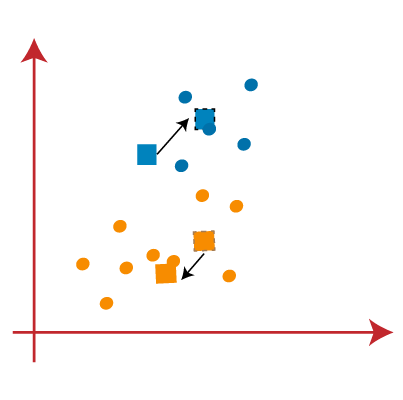
STEP 6:Equally reassignment has taken identify, so we will repeat the to a higher place step of finding new centroids.
Stride 7:We volition echo the above process of finding the center of gravity of centroids, every bit beingness depicted below
Stride 8:Later on Finding the new centroids we will again draw the median line and reassign the data points, similar the in a higher place steps.
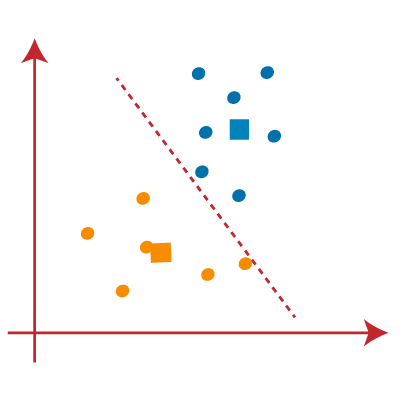
STEP 9: We will finally segregate points based on the median line, such that two groups are being formed and no different betoken to be included in a single group
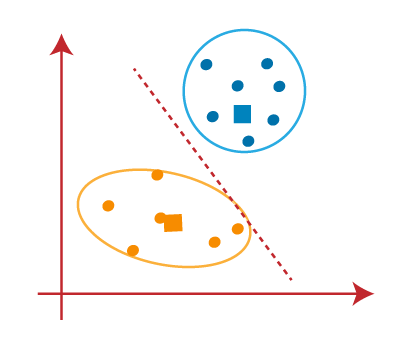
The final Cluster being formed are equally Follows
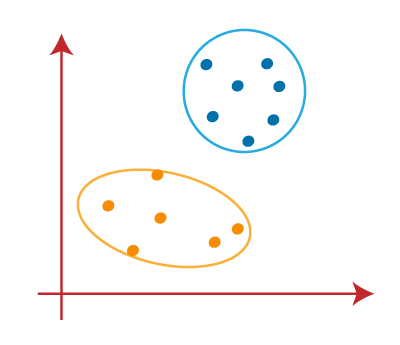
4. Choosing The Right Number Of Clusters
The number of clusters that nosotros choose for the algorithm shouldn't exist random. Each and Every cluster is formed by computing and comparing the mean distances of each data points within a cluster from its centroid.
We Can Cull the right number of clusters with the help of the Inside-Cluster-Sum-of-Squares (WCSS) method.
WCSS Stands for the sum of the squares of distances of the data points in each and every cluster from its centroid.
The main thought is to minimize the altitude betwixt the information points and the centroid of the clusters. The procedure is iterated until we achieve a minimum value for the sum of distances.
To observe the optimal value of clusters, the elbow method follows the below steps:
1 Execute the One thousand-means clustering on a given dataset for different G values (ranging from 1-10).
2 For each value of Yard, calculates the WCSS value.
iii Plots a graph/curve between WCSS values and the corresponding number of clusters Yard.
4 The sharp betoken of bend or a bespeak( looking like an elbow joint ) of the plot like an arm, will exist considered as the all-time/optimal value of Thou
five. Python Implementation
Importing relevant libraries
import numpy every bit np import pandas as pd import statsmodels.api as sm import matplotlib.pyplot every bit plt import seaborn every bit sns sns.set() from sklearn.cluster import KMeans
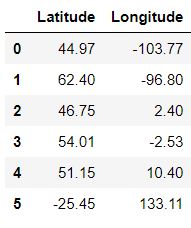
Loading the Data
data = pd.read_csv('Countryclusters.csv') data 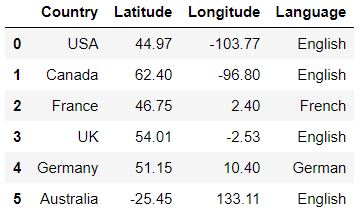
Plotting the data
plt.besprinkle(data['Longitude'],data['Latitude']) plt.xlim(-180,180) plt.ylim(-90,xc) plt.show()
.png)
Selecting the feature
ten = information.iloc[:,1:3] # 1t for rows and 2d for columns x
Clustering
kmeans = KMeans(3) means.fit(x)
Clustering Results
identified_clusters = kmeans.fit_predict(10) identified_clusters
array([1, 1, 0, 0, 0, 2])
data_with_clusters = data.copy() data_with_clusters['Clusters'] = identified_clusters plt.besprinkle(data_with_clusters['Longitude'],data_with_clusters['Breadth'],c=data_with_clusters['Clusters'],cmap='rainbow')
.png)
Trying different method ( to discover no .of clusters to be selected)
WCSS and Elbow Method
wcss=[] for i in range(1,seven): kmeans = KMeans(i) kmeans.fit(10) wcss_iter = kmeans.inertia_ wcss.append(wcss_iter) number_clusters = range(1,7) plt.plot(number_clusters,wcss) plt.championship('The Elbow championship') plt.xlabel('Number of clusters') plt.ylabel('WCSS') .png)
we can choose 3 as no. of clusters, this method shows what is the good number of clusters.
With this, I cease this blog.
Hello Anybody, Namaste
My name is Pranshu Sharma and I am a Data Scientific discipline Enthusiast
Cheers so much for taking your precious time to read this weblog. Experience free to point out whatsoever mistake(I'm a learner later on all) and provide corresponding feedback or leave a comment.
Dhanyvaad!!
Feedback:
Email: [email protected]
The media shown in this article are non owned by Analytics Vidhya and is used at the Writer's discretion.

How To Use K&n Air Filter Cleaner,
Source: https://www.analyticsvidhya.com/blog/2021/04/k-means-clustering-simplified-in-python/
Posted by: smiththared1978.blogspot.com
0 Response to "How To Use K&n Air Filter Cleaner"
Post a Comment